コントローラーが故障したraid5ディスク上のDBバックアップはどこに格納されていたか @karo-jp

赤きLEDの明滅とビープ音
とある20世紀末の夏。
「データセンタ」を謳う19インチラック7台ほどのサーバルームの中で、DELLやCompaqのLEDが明け方の空に瞬く星々のように明滅を繰り返していた。そろそろメジャーになりつつあった青色LEDが、緑やオレンジの輝きの中に混ざり、冷涼な室内をさらに涼しく彩る。
しかし、赤色LED。お前はダメだ。
サーバ機器、ネットワーク機器に光る赤色LEDは、ハードウエアの不具合を示す。
俺はクライアントから、顧客管理システムでエラーが出ている、との連絡を受けた。
クライアントのシステムが収められた「データセンタ」に入室すると、甲高いビープ音が室内に鳴り響いているのに気づく。「データセンタ」は稼働したばかりで運用経験が浅く、俺にはどの機器が泣いているのか、音だけで聞き分けることはできなかった。が、幸い、ラック7台に過ぎない小さな「データセンタ」は、程よく全体への見通しが良いため、すぐに赤いLEDが明滅する機器に目が行く。
DELL PowerVault、3.5インチのHDDが多数搭載されたストレージ機器だ。
SQL Server
そうだ、こいつだ。こいつは今回連絡を頂いたクライアントが保持する大容量データの為に最近購入し、最新鋭のMicrosoft SQL Server 7.0 用のストレージとしてセットアップしたヤツだ。
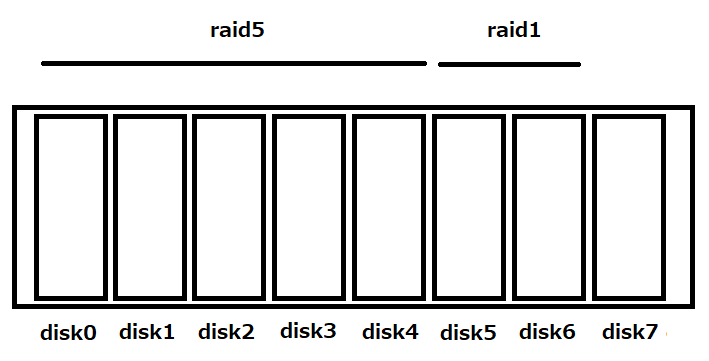
Raid5は最強
ディスクの故障だろうか。
しかし心配無用。ディスクの故障に備え、こいつはRaid5とRaid1で組んである。Raid5なら、ディスクが1台や2台故障しても、故障したディスクを交換すれば問題なく復帰できる。おまけにこいつはホットスワップ対応、電源を落とさずにディスクの交換をすることができる。予備のディスクも用意してある。
ディスクの故障は初めての経験だった。本当に復帰するんだろうか、という心配も多少あったが、DELL PowerVaultのRaid5は最強、と、根拠のない安心感が心配を払拭し始める。俺は赤く光るディスクを引き抜き、予備のディスクを挿し込んだ。
ビープ音再び
新しいディスクを挿し込むと、直ぐに挿し込んだ新品のディスク以外も含め、全ディスクの緑色LEDが瞬きはじめた。
再構築が始まる。再構築が終わるまで、いかほどの時間が必要なのだろう。
外は暑い。俺は再構築完了まで、「データセンタ」の中でのんびり涼むことにした。
数分後、再びビープ音が鳴り響いた。
交換したディスクも壊れていたのか。俺は別の予備ディスクを手に取り、つい数分前に交換したディスクを抜き、差し替える。
しかし、ストレージが復旧することはなかった。
バックアップからの復旧
涼しいはずのデータセンタが少しも涼しくない。
額からは汗が吹き出し、手のひらは湿り気を増す。
相変わらずSQL Server から、ストレージへのアクセスは復帰しない。幸い、リアルタイムのアクセスを要求されるシステムではなかった為、クライアントからの催促はまだない。数時間のうちに復旧し、「直りました。ディスクにエラーが出てましたよ。幸い、交換可能な構成にしといたので、大事には至りませんでした。」と報告すればいいはずだ。
そうだ、DBデータはD:ドライブ、バックアップをE:ドライブに取るよう設定していた筈だ。
まずはバックアップデータをサルベージの上、PowerVaultを切り離してPowerEdgeサーバにディスクを足して単体でSQL Server を稼働させよう。PowerVaultの問題解決は後回しだ。
バックアップの保存先
さて、E:ドライブからDBバックアップファイルをサルベージしようか、というところで俺は思い出した。
Raid5で構成された仮想ディスクをパーティションでD:ドライブとE:ドライブに分けていた事実を。
いや、本当は最初から気づいていたのだろう。
Raid5で組まれたディスクにアクセスできなかった時から、DBデータは永久に失われていた事を。
土下座による再構築
クライアントへは何をどのように報告したか、記憶が定かではない。
数千件の顧客情報を含むDBが破壊され、「ハードウエアのトラブル」によりデータが永遠に失われてしまった事実を伝えたことは確かだ。
憶えているのは、クライアントが大変寛大であり、全く怒ることも、騒ぐこともなく、冷静に聞いてくれた事だ。
後日、DBサーバは別の機器で再構築され、バックアップはDATドライブへ取るよう、再構築。
データは「クライアント自ら」「紙情報から再入力」することにより復旧を遂げた。
俺は、このクライアントの為ならたとえ深夜2時だろうが駆けつけて対応しよう、と、心に誓った。
後日譚
後日、調査により、ディスクではなく、「Raidコントローラ」が故障していたことが判明した。
どのような挙動があったのか不明だが、全てのディスクに「正しくない」情報が書き込まれ、ストレージとして機能していなかった、との事。
Raid1で組まれていた別ドライブも、使い物にならなくなっていた。確かRaid1のドライブにも、時折バックアップファイルをコピーしていた筈だが、それも失われていた…ことはあとになって気づいた。
この物語に教訓なんてものは何も無い。単に、何も考えずにシステム構成を考えたクソなエンジニアが、寛大なクライアントに心を救われた、というだけの話だ。
…それだけではクソすぎるので教訓じみた事を書き殴ろう。
惨劇の根本的原因
- リスク分析が十分ではなかった。Raidコントローラーだって壊れる。壊れた際の影響度は計り知れない。
- raid に対する本質的理解が足りなかった。Raid5のパリティによる冗長化を、データが消えない魔法の呪文と思っていた。
- システム設計のレビューが十分ではなかった。同じ環境・デバイスへのバックアップは無意味。
教訓
- 万物は壊れる
すべての構成要素は必ず不具合を生じる前提で物事に当たれ。AWS
- 自分を信じるな
いい感じで設計できた、実装できたと思っても、必ず自分以外にレビューをしてもらうべきだ。
- クライアントとは常にいい関係を維持しろ
もしクライアントが普段から嫌な思いをしていたら、と思うとゾッとする。人間関係は良好に保とう。
- 真実は友達
不都合な事実であろうとも、誠意を持って伝えよう。伝える深度は調整してもいいかもしれない…
※このポエムはほぼ100%の事実をもとにしたフィクションです。製品名、製品仕様については20年以上前ということもあり、曖昧で適当です。
単語メモ

- ホットスワップ:機器の電源を入れたまま稼働状態を保ち、部品やケーブルなどを交換・装着することです。
- SQL Server(Microsoft SQL Server):データベース管理システムです。企業で利用されることが多いデータベース管理システムです。
- 仮想ディスク:ディスクドライブ仮想化ソフトで、記録媒体の内容をイメージファイルに保存し、それを開くとソフトウェアに記録媒体がマウントされている状態にします。あたかもその記録媒体をドライブに挿入しているかのように制御するソフトウェアです。
- パリティ:データがおかしくなっていないか確認する方法です。送られてきたデータが途中でおかしくなっていないか、チェックをする方法のひとつです。
クラスタのノード欠損を復旧しようとしてクラスタを丸ごと落とした話 @Yutaka_Nakano

これは、私が若…くはないけどピカピカのAWS1年生だった、数年前のお話です。
何をやらかしたのか
やらかし前の状態
本番運用しているWebアプリケーションの裏側に、EC2インスタンス3台でクラスタを組んだ某データストア製品を使用していました。データはクラスタ内でレプリケーションされており、1台がダウンしただけならクラスタは稼働を継続できます。2台がダウンするとクラスタ全体が機能しなくなります。
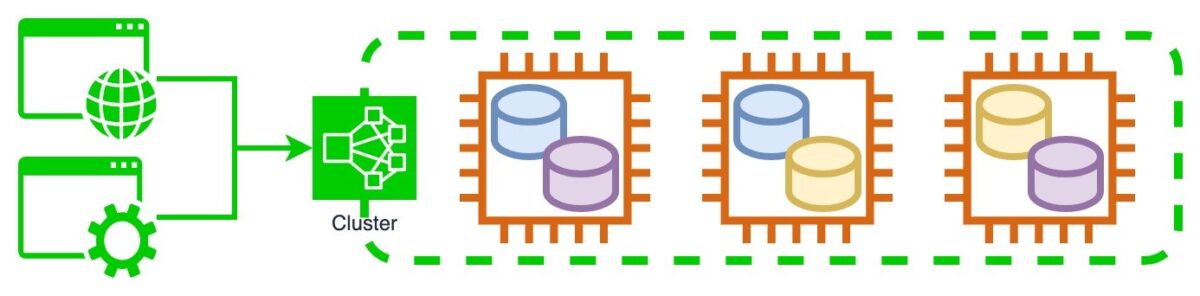
ある日、3台のうち1台で障害が発生してインスタンスへ疎通できない状態になりました。この時点ではクラスタは正常に応答しており、あと1台ダウンしない限りはサービスに影響が出ない状態でした。
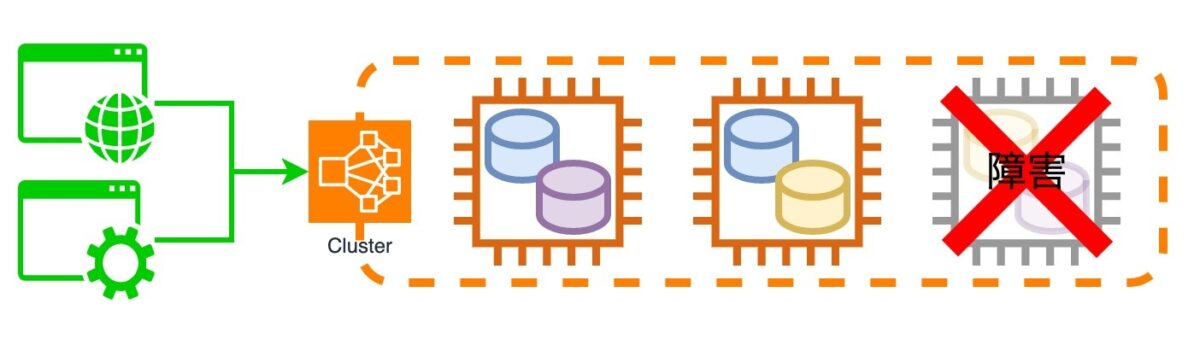
まず、ダウンしてしまったインスタンスを再起動して復旧させようとしました。ところがEC2マネジメントコンソールから再起動、停止を選択しても障害中のインスタンスは反応しません。そして私は間違いを犯します。
やらかしたこと
この日は休日の午前であり、一番詳しい人はまだ寝ているようです。私は焦りました。
「やばい。早く3台構成に戻さないと、あと1台止まったらクラスタ全体が止まってしまう。」
既存のサーバが壊れてしまったなら、新しくサーバを作ってクラスタに参加させるしかありません。サーバのセットアップには複数のセットアップスクリプトを実行する必要があり、焦った状態で正しく実施できる自信がなかったので、正常稼働中インスタンスのディスクを元に新たなインスタンスを起動しようとしました。そしてAWS EC2コンソールで稼働中のインスタンスを選択して、 アクション > イメージ > イメージの作成 を実施しました。
操作を終えて数秒後、我に返りました。あれ今「再起動しない」って項目なかった? しかもチェック外れてなかった? もう一度イメージ作成画面を開いてみよう。

あっっ
やらかした結果何が起きたのか
私は悟りました。ノード喪失に耐えて正常稼働していたクラスタに、自らの手でとどめを刺してしまったのだと。
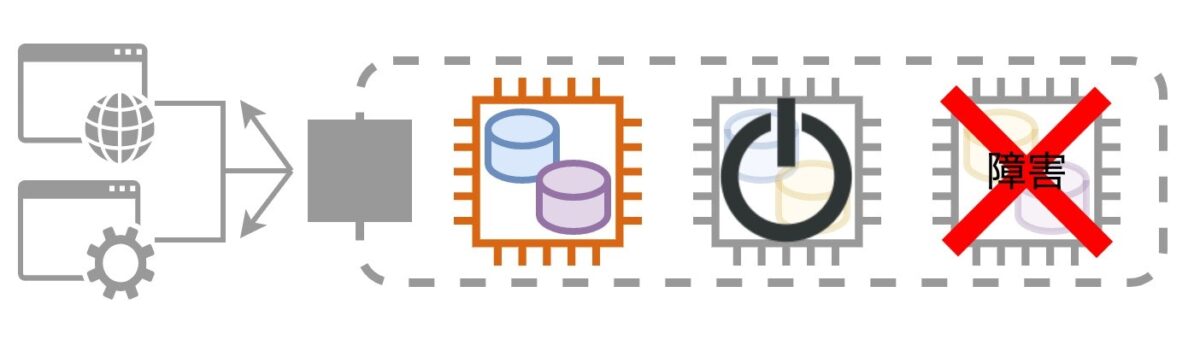
3台中2台が残り正常稼働していたデータストアのクラスタでしたが、再起動のために追加で1台が止まった結果、クラスタ全体が停止して無応答になりました。そして、そのクラスタに依存していた複数のWebアプリケーション機能しなくなり、再起動が完了するまで数万回のアクセスに対してエラーで応答し続けたのでした。
惨劇はなぜおこってしまったのか
この惨劇は複数の判断ミスが連続したことによって生まれています。
やばい。早く3台構成に戻さないと
やばくありません。1台倒れても大丈夫なための冗長構成です。焦って本番を弄り回すほうがやばいのです。
既存のサーバが壊れてしまったなら
実は、もう少し待てば既存のサーバが復旧してきたのですよ…判断が拙速でしたね。
サーバのセットアップには複数のセットアップスクリプトを実行する必要があり、焦った状態で正しく実施できる自信がなかった
セットアップスクリプトを整理しておいてください。というか、セットアップ手順も分かってないのによく本番を触ろうと思ったな。
正常稼働中インスタンスのディスクを元に新たなインスタンスを起動
正規の手順でセットアップしなさい。思いつきで適当な操作をするな。
あれ今「再起動しない」って項目なかった? しかもチェック外れてなかった?
ダイアログをちゃんと読みなさい。
そして、誤判断の裏には障害に対する準備不足という根本原因がありました。
二度と惨劇を起こさないためにどうしたのか
2度とこのような失敗を起こさないために、障害対応手順の明記と障害対応訓練を実施しました。
障害対応手順の明記
既存のノード復旧を待つか、新規ノードを作成するかの判断のポイント。どんな手順で対応すればよいか等々、明確で正確な障害対応手順書を作りました。(なかったんかい!!
障害対応訓練
開発環境で実際にクラスタの一部ノードを落とし、手順に従ってアプリケーションに影響を出さずに復旧できることを確かめつつ、障害対応の訓練をしました。対応手順には操作に対する反応に応じて次の行動を決める分岐があり、繰り返し訓練を行って全パターンを網羅的に確認しました。
次に同じ障害が起きても、何の問題もなく対処できるはずです(それが普通です…)
蛇足
この記事では盛大にやらかしている私ですが、成果も出してるんですよ常にやらかしてるわけではないんですよ、ということで別のアドベントカレンダーへのリンクを貼らせてください。今年はSupershipグループとElastic Stack (Elasticsearch) のアドベントカレンダーに参加します。こちらも目を通していただけると幸いです。
単語メモ
- AWS(アマゾン ウェブ サービス):世界で最も包括的で広く採用されているクラウドプラットフォームです。
- インスタンス:事実、事例などの意味を持つ英単語で、ソフトウェアの分野では、あらかじめ定義されたコンピュータプログラムやデータ構造などをメインメモリ上に展開し、処理・実行できる状態にしたものです。
- クラスタ:群れの意味です。ネットワークに接続した複数のコンピューターを連結して1つのコンピューターシステムに統合し、処理や運用を効率化するシステムです。
- レプリケーション:複製を作ることの意味で、同じネットワーク内もしくは遠隔地にサーバーを設置し、リアルタイムにデータをコピーする技術です。
- マネジメントコンソール:管理するためのツールです。
- スクリプト:簡易なコンピュータプログラムのことです。
- ダイアログ:ダイアログボックスのことで、何かを入力したり、メッセージを確認させるために操作の過程で一時的に開かれる小さい画面のことです。